I now made an update on Units of Measure (available on request)
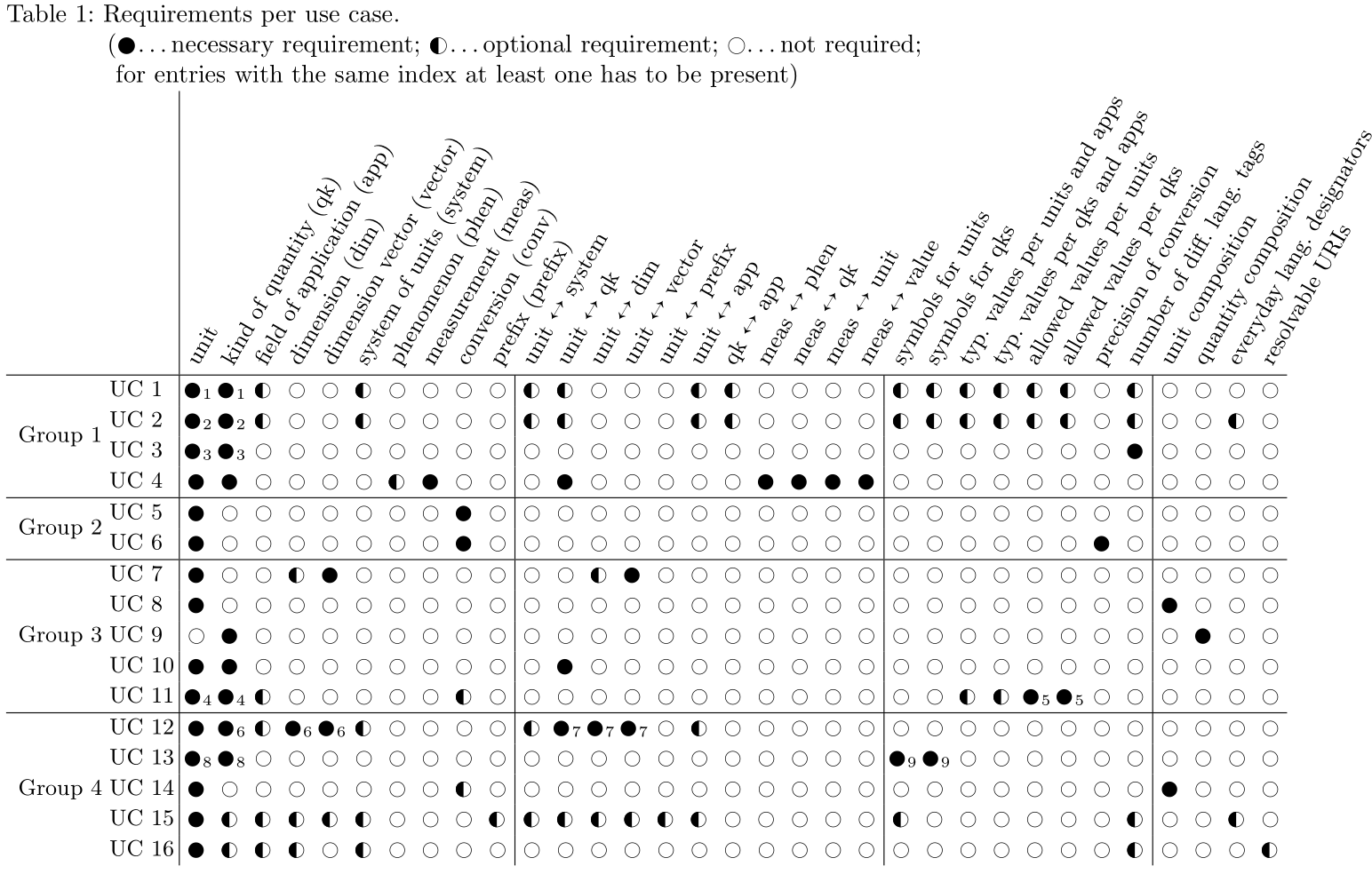
1.2 Crucial Questions
Crucial Questions to consider when designing ECLASS RDF.
Together with the use cases and competency questions, they should provide a frame of reference
for making decisions that are usable, consistent, viable in the long term.
Data Copying vs Data Decentralization
Decentralization and Semantic Web Principles
Data Copying
Ontological Realism vs Idiosyncrasy
Step-by-Step Guide to Ontology Development
Closed vs Open Data Ecosystems
Local vs Global Thinking
While I have my doubts that the ECLASS Association will be able to soon subscribe to these principles, I believe they are important considerations to keep in mind.
1.2.1 Semantic Web Principles
Semantic Web and Linked Data are based on several simple principles:
Everything has a IRI (URL): from a huge enterprise, to its plants, to every machine and asset, to each document and data spec, to the smallest measurement or data field.
The data model is simple (abstracted). It's a semantic graph made of triples (relations that are graph edges, and attributes that are literal values).
RDF is flexible: can be used without or with schemas; schemas stored the same as data, can always be extended, without requiring system redeployment or data migration.
In appropriate settings, a data consumer can rely that data about any entity will be returned when its IRI is dereferenced.
1.2.2 Decentralization
Data Decentralization (Distribution)
each party holds its data and allows other parties to access it at any time (as appropriate, controlled by license agreements and access rights).
an important technological element of Data Sovereignty, as propounded by the International Data Spaces Association.
better approach to cross-enterprise data integration, as evidenced by boom of Semantic Data Integration and Enterprise Knowledge Graphs.
a system will often want to make a local copy of global data (caching), but this is engineering not data architectural principle
1.2.2.1 Data Copying
As far as I can see, most Industry data still relies on Data Copying (or Exchange).
Copies of data are transferred between parties
Global IRIs are sparingly used and don't have "first class citizen" status
There is no assumption that the up-to-date Version of Record of a fine-granularity piece of data will always be found at a certain IRI.
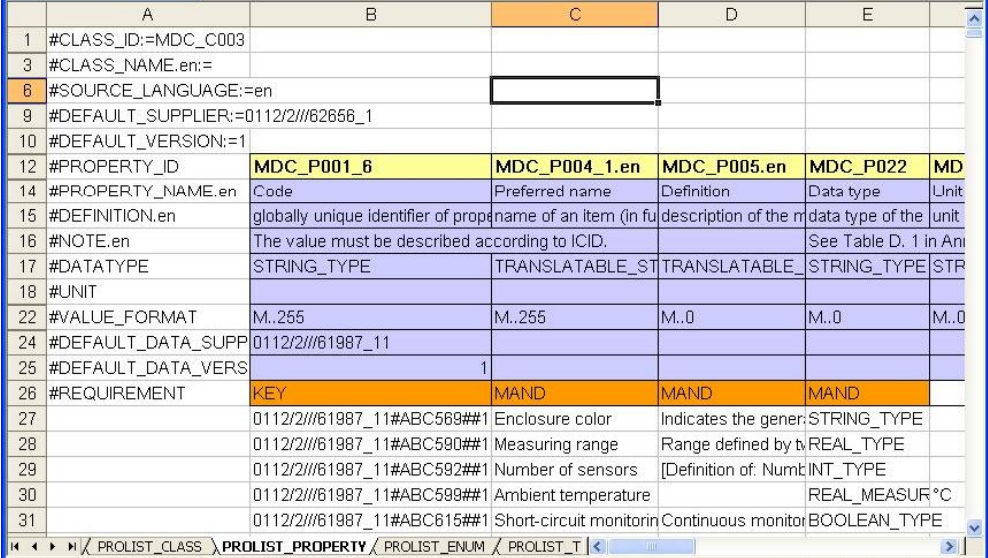
ECLASS distributions,
BMEcat transfers,
IEC CDD unavailability of IRDIs for global resolution,
RAMI/AAS examples of copying other data into an admin shell, etc.
I believe that ECLASS RDF should break out of this tradition and tackle directly Data Distribution.
Exception: ISO 15926 (oil & gas) and its Reference Data Libraries
1.2.3 Ontological Realism vs Idiosyncrasy
an ontology should be analogous not to a data model, but rather to a reality model
ontological realism positions the resulting ontologies as best candidates for serving as common models of all the data sources within a complex information ecosystem
realist ontologies enable cross-enterprise-wide data integration by removing a layer of perspective from each of the several data sources involved
Compare:
The real world of economy/manufacturing has products, product classes, properties, manufacturers, documents, spec sheets, etc
The PLIB (OntoML/POM) world of idiosyncratic information artifacts has classification classes, characterization classes, application classes, blocks, aspects, etc.
1.2.3.1 Step-by-Step Guide to Ontology Development (excerpts)
Identify the primary bodies of data your ontology will be used to annotate.
Maximize the ability of your ontology to address these primary tasks
but without detriment to its ability to address secondary uses not yet identified.
(secondary uses are often significantly more important than primary uses, and almost always what guarantees the enduring value of an ontology)
ensure that the terms and definitions in your ontology are of broad understandability and validity
(rather than being understandable and valid only by your immediate collaborators and only when used in relation to your currently available data)
Do not confuse information artifacts with the reality they denote
Distinguish explicitly between each real entity and the information about it
Eg gtin is a prop of ProductModel but gln is a prop of an Organization
1.2.4 Open vs Closed Data Ecosystems
ECLASS is a very closed data environment: it does not reuse data by anyone else. Eg:
Although it uses same/similar data model as IEC CDD, it does not use any IEC data, not even IEC Units of Measure.
It defines various lists that should not be the business of ECLASS, eg: Countries, Languages, Colors, Units of Measure, etc
Why should ECLASS care about this?
Reusing data representations and data items created by others may reduce the work of ECLASS.
(I acknowledge that this does not hold in all cases because sometimes it's easier to produce data in a closed environment.)
Reusing data may make it easier for ECLASS users to consume ECLASS:
ECLASS product data is only one kind of data in an enterprise IT environment
There is a large number of ontologies relevant to the use cases that ECLASS cannot interoperate with
That includes IoT/WoT, schema.org, sensors, electrical, green energy, BIM, etc, etc
1.2.5 The Web: Open Innovation
W3C standards are fully open:
Preceded by UCR (Use Case Requirement specifications) that are gathered through wide consultation
Openly developed (usually on github), anyone can submit issues
Models (ontologies), test suites and test results (EARL ontology) are all expressed in machine-readable way (usually RDF)
Before accepted as recommendation, minimum 2 conforming implementations are needed. Implementation Report is generated from EARL RDF
1.2.6 The Web Invites Wide Participation
Anyone can make content and link to other content
World Wide Web of content (web) and Global Giant Graph of data (semantic web)
Working Groups and Community Groups
"Permission-free innovation"
Unfortunately, big "internet properties" have become content monopolists: so TimBL started the Solid web decentralization project
1.2.7 ISO and IEC: Closed Standards
ISO and IEC standards are closed:
Eg ISO 13584-32:2010 Industrial automation systems and integration — Parts library — Part 32: Implementation resources: OntoML: Product ontology markup language
Development by a close expert group
Long and bureaucratic development and update cycles
Delivered as PDF with few machine-processable artefacts
Costs 200 CHF: few developers will bother to pay this to get it
1.2.8 ISO and IEC: Positive Aspects
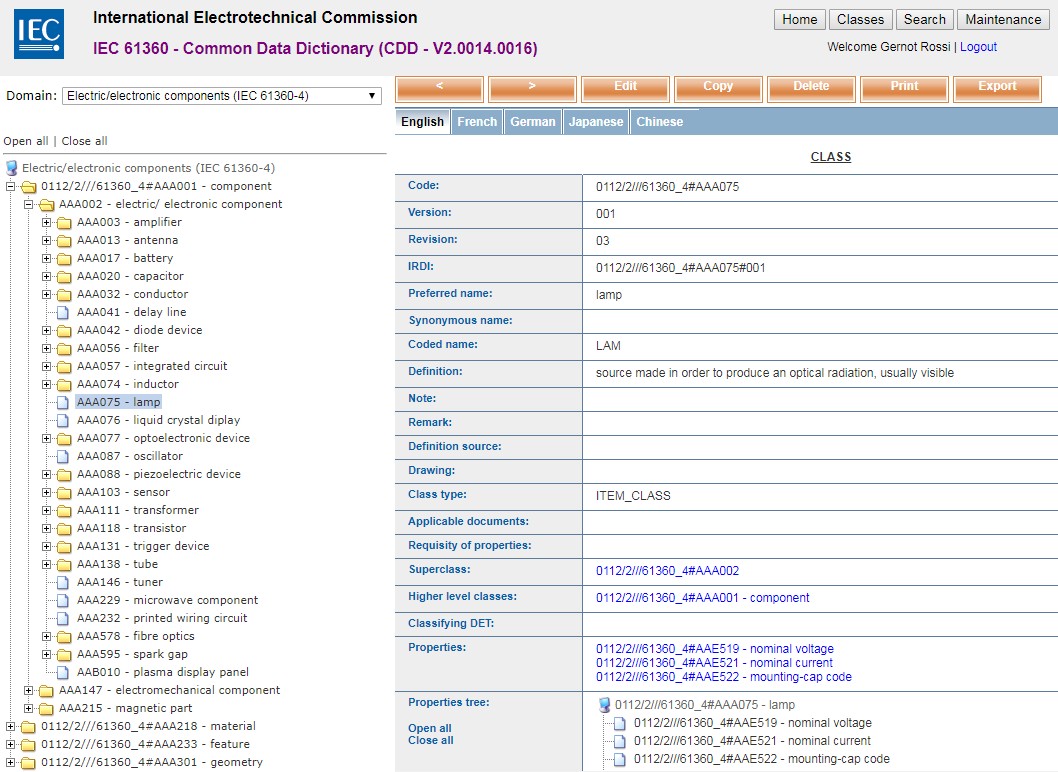
IEC CDD is online, open (but not quite), update a lot more frequently
YOU may not sell, lend, lease or distribute to a third party, reproduce or otherwise exploit, whether commercially or not, the total database or a significant portion of it, to which this LICENSE relates .
YOU may copy the database only for a restricted and confidential internal use and this LICENSE exception is also restricted to other employees for their internal or external use within YOUR organization.
Only partial dumps available
ECLASS is not available online in machine-readable form
ECLASS is paid and that is fine: "Open" is not the same as "Free"
But the Association must consider carefully who are its paying customers and what should be its licensing model
I think manufacturers should pay, but not eCommerce or WoT developers
1.3 Local vs Global Thinking
PLIB & ECLASS define everything locally
Internal data items are not intended for online access (eg IRDI Versioning)
External LOD is never reused, although readily available, eg
Defined Competency Questions are the best way to guide ontology development
To avoid going off on a tangent and designing too much of what's not needed
In our case we start from a well-developed information model, so we should capture all of it
But we still need to answer:
What will consumers want to search for or search by?
Eg are these legit queries "find red products", "find products shorter than 15cm"?
Are these easy to answer? I haven't seen many/any sub-properties in ECLASS?
Eg there isn't a single "height", there's also "height of enveloping body"
That applies to "enveloping body - cylinder" and "enveloping body - box"
There are different props that relate to those Polymorphic blocks
What data do they want to get? Tradeoff:
Don't get too much (eg only definitions of props actually used in a product)
Don't get too little (to avoid too many network round-trips)
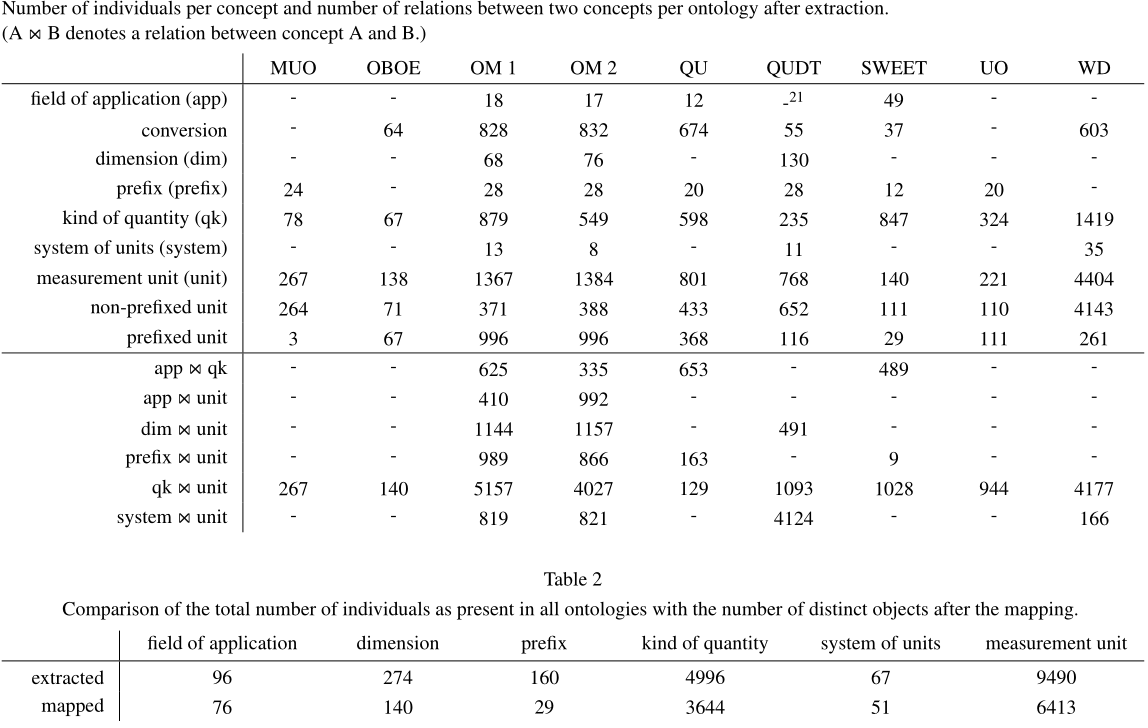
2 Related Work
Various previous works are relevant for the ECLASS effort.
Martin Hepp: GoodRelations, product classifications, product catalogs
schema.org Product classes: relevant for all web sites and more; simple pragmatic modeling
Application Profiles and RDF Shapes
XSD data types: everyone uses them (even schema.org that declares its own datatypes)
Unit of Measurement Ontologies: 3 are widely established and used
2.1 Martin Hepp
Martin Hepp's work on semantic web approaches to eCommerce is well-known and established:
GoodRelations (products, offers, prices) is the foundation of eCommerce in schema.org
The "Gen/Tax" distinction between strict class hierarchies and vaguer taxonomic (classification) hierarchies
Conversion of a number of product ontologies to RDF/OWL, although in a simplistic way
I'm sure ECLASS has taken into account his experiments, but we can turn back to his work for more advice and guidance.
Below I list Martin's papers that are relevant to this effort.
Comparison/Overview of product description vocabularies:
Product Representation in the Semantic Web (Working Paper 2004-04)
Content Metrics for Products and Services Categorization Standard (EEE 2005)
A Quantitative Analysis of ECLASS, UNSPSC, eOTD, and RNTD Content, Coverage, and Maintenance (ICEBE 2005)
The True Complexity of Product Representation in the Semantic Web (ECIS 2006)
A Quantitative Analysis of Product Categorization Standards: ECLASS, UNSPSC, eOTD, and RNTD (KAIS 2007)
2.1.1 Martin Hepp (2)
Conversion Methods:
SKOS2OWL- An Online Tool for Deriving OWL and RDF-S Ontologies from SKOS Vocabularies (ISWC 2009 poster)
A Methodology for Deriving OWL Ontologies from Products and Services Categorization Standards (ECIS 2005)
Representing the Hierarchy of Industrial Taxonomies in OWL- The gen-tax Approach (ICSW 2005)
Products and Services Ontologies- A Methodology for Deriving OWL Ontologies from Industrial Categorization Standards (IJSWIS 2006-01)
GenTax- A Generic Methodology for Deriving OWL and RDF-S Ontologies from Hierarchical Classifications, Thesauri, and Inconsistent Taxonomies (ESWC 2007)
Alignment of Ontology Design Patterns- Class As Property Value, Value Partition and Normalisation (OTM 2012)
Specific Product Classifications:
PCS2OWL- A Generic Approach for Deriving Web Ontologies from Product Classification Systems (ESWC 2014)
ProdLight- A Lightweight Ontology for Product Description Based on Datatype Properties (BIS 2007)
Product Ontology website documentation
2.1.2 Martin Hepp (3)
ECLASS:
ECLASSOWL- The Web Ontology for Products and Services (2010-04) website documentation
Integrating Product Classification Standards into Schema.org- ECLASS and UNSPSC on the Web of Data (OTM 2017)
ECLASSOWL- A Fully-Fledged Products and Services Ontology in OWL (ISWC 2005 Poster)
Using BMEcat Catalogs as a Lever for Product Master Data on the Semantic Web (ESWC 2013)
ISO 13584 (PLIB):
Ontologizing B2B Message Specifications- Experiences from Adopting the PLIB Ontology for Commercial Product Data (ICEBE 2006)
A Critical Assessment of ISO 13584 Adoption by B2B Data Exchange Specifications (ICCE 2006)
2.2 schema.org
Schema.org describes many real-world entities, is applicable in a wide variety of domains, and integrates data from a huge number of providers and domains
It is used more and more often on actual eCommerce sites (see Use Case above)
WoT efforts make a connection to schema.org, and use the same "low ontological commitment" as schema.org
2.2.1 RDFS/OWL: High Ontological Commitment
RDFS defines the properties rdfs:domain and rdfs:range
These are strict and "prescriptive":
According to RDFS semantics, every time the described property is used, the property subject resp. object gets the domain resp. range as type.
This also makes these RDFS properties "monomorphic": they should take single values, otherwise the subject/object will get multiple types, which are usually not intended.
Eg if you state that name is applicable to Person and Organization with the axiom :name rdfs:domain :Person, :Organization,
entities with name will become bothPerson and Organization, which is an often made mistake.
Ontology engineers overcome this problem by:
introducing abstract superclasses (e.g. Actor or even Nameable),
using owl:union to make a disjunction of several classes, or
using owl:Restriction to bind the property to the class locally.
But all of these approaches complicate the ontology, increase "ontological commitment", and ultimately make ontology reuse harder.
2.2.2 schema.org: Low Ontological Commitment
To cope with web-scale integration of data, Schema uses properties schema:domainIncludes and schema:rangeIncludes
These are advisory and "descriptive" (describe properties applicable to a class, without being exclusive)
Therefore polymorphic: an axiom like :name schema:domainIncludes :Person, :Organization doesn't cause any unintended types to be inferred
This approach has much lower "ontological commitment" and enables more flexible reuse and combination of different ontologies
So it is appropriate in any data domain where data comes from a large number of sources
Rather than using complicated OWL mechanisms, we prefer to use RDF Shapes to validate incoming data from data providers
We used this mechanism for Company data, see the euBusinessGraph Ontology cited above
It is also used in the WoT Thing Description ontology
2.2.3 Schema.org Specific Classes
schema.org has several releant classes. Should be considered for reuse:
ProductModel: A datasheet or vendor specification of a product (in the sense of a prototypical description).
Product: Any offered product or service. For example: a pair of shoes; a concert ticket; the rental of a car; a haircut; or an episode of a TV show streamed online.
PropertyValue: A property-value pair representing an additional characteristics of the entitity, e.g. a product feature or another characteristic for which there is no matching property in schema.org.
QuantitativeValue: A point value or interval for product characteristics and other purposes.
Might be relevant:
ProductGroup: a group of Products that vary only in certain well-described ways, such as by size, color, material etc.
EnergyConsumptionDetails: the energy efficiency Category ("class" or "rating") for a product according to an international energy efficiency standard
2.2.4 Schema.org Specific Props
schema.org also has some fixed product properties.
Can be useful if you decide to replace some IRDIs with named terms:
unitCode which is either based on UNECE/UNCEFACT (eg MTR), can use a prefixed name (eg ucum:um for micrometers), or a URL (eg qudt:Meter)
Links like isAccessoryOrSparePartFor, isRelatedTo, isSimilarTo, isVariantOf, inProductGroupWithID, manufacturer
Identifiers like gtin, mpn, nsn, productID, sku, identifier
Classification extensions like additionalType, category
Both the first and second ECLASS RDF representations closely mirror OntoML.
Pros: represents all ECLASS information
Any alternative approach should take this into account
Cons:
Uses complicated RDF modeling, eg properties are not mapped to RDF properties but to classes
Innate OntoML problems, see next
3.1 OntoML Problems
OntoML is (arguably) not logical and not semantic
(Despite the name and being an ISO standard)
Not an open standard
Niche terminology
No realism: deals with information modeling artefacts not real-world (physical) artefacts
Uses its own datatypes
Uses its own units of measure
Not oriented towards linked data
Based upon local not global thinking
3.1.1 RDF/RDFS/OWL: Simple, Logical
RDF is a very simple data model based on predicate logic: triple s p o corresponds to predicate p(s,o)
RDFS and OWL have strong logical foundations: Set Theory, First Order Logic, Description Logics
OWL was developed through a rigorous process and many experts in logic, datalog, logic programming and databases were involved
OWL2 was added after practical experience
Many studies on the complexity of various OWL fragments
Defined complexity/reasoning profiles: RDFS, RDFS+, OWL Lite, RL, QL, DL, EL, Full (eg see naive OWL Fragments map)
Some of the best ontologies follow principles of Realism
3.1.2 OntoML: Complicated, Not Semantic, Not Logical
Complicated XML model
Does not have grounding in Realism
Does not have grounding in logic or logic programming
No opportunities for inference (or at least nobody has investigated this)
No subclass and subproperty relations?
3.1.3 OntoML: Niche Terminology (1)
Very few people will take the time to read and understand OntoML, and fewer will use it correctly.
Here's an attempt at "translation" (please excuse me if I got some OntoML terms wrong).
OntoML
RDF/OWL
classification class
Conceptual hierarchy, probably skos:Concept in ConceptScheme
characterization class
Product class (eg ec:ProductClass)
application class
Product class; the basic/advanced distinction should be handled through Profiles
product model
schema:ProductModel (in manufacturer catalog, refers to ec:ProductClass)
property
Property, with rich definition
reference
Object Property linking to product or part
attaching property to class
OWL DL owl:Restriction or schema:domainIncludes or RDF Shape
synonym/alias
Property altLabel
keyword
Class altLabel or keyword/subject
3.1.4 OntoML: Niche Terminology (2)
OntoML
RDF/OWL
block
Product part (but need to confirm whether all "blocks" are parts)
aspect
Class holding additional information (eg Manufacturer, Supplier, Customs info, etc)
cardinality
Numbered product part
polymorphism
Named product part
depending property
RDF Shape describing the dependency
value list
Enumerated class (owl:oneOf) or skos:ConceptScheme or schema:DefinedTermSet
value
Object
explicit value
Literal
coded value
Individual from an enumerated class
domain
Property range (class or datatype)
unit
Unit of Measure ontologies
level
Property qualifier (eg min, max), need to also include current, stdev etc
3.1.5 OntoML Uses its Own Datatypes
For basic data, OntoML uses its own classes:
OntoML:Datatype class
Labels: several classes (eg OntoML:preferred_name) with fields label, language_code, country_code
This is not economical, people will not waht to use that in RDF.
Note: some other industrial ontologies make the same mistake, eg IFCowl, which has datatypes with legacy to EXPRESS
As a counter-point, alterantive transations of IFC has appeared and alternative Linked Building Data ontologies
3.1.6 OntoML Uses its Own UoM
OntoML is a closed information ecosystem, so it promotes the use of own Units of Measure (UoM)
IEC UoM (eg see quantity mass density and its list of units): large number, but no dimensional analysis, no conversion factors.
ECLASS UoM: no dimensional analysis (AFAIK), proper conversion factors.
Maybe ECLASS should not attempt to be an authority on UoM?
Evaluate against the two UoM evaluation papers
How many units does ECLASS have?
Option1: use established units (QUDT or LINDT)
Option2: use ECLASS units, but express with QUDT properties
3.1.7 OntoML: Local vs Global Thinking
OntoML is based upon local not global thinking. Examples:
Embedded list of country codes, but ECLASS should not attempt to be a geographic authority
Authoritative LOD sources are available: Geonames on all kinds of places, and many up to date country lists
Embedded lists of languages. But there are many comprehensive linguistic resources:
IANA lang tags as mentioned above
lexvo, lingvo, etc LOD sites
Embedded list of Materials: has a few hundred items, but there are many industry-specific lists:
Chemicals
Grades of steel and formulations of alloys
New materials (eg nanomaterials, graphene...)
Embedded copy of the MIME Types list (type of source file)
Includes duplicates (eg application/x-sh, application/x-tcl)
Excludes many modern types and combination types (eg text/turtle, application/rdf+xml, application/json, application/ld+json)
Colors: insufficient for professional design use (eg think Panathon colors)
3.1.8 OntoML: Not Oriented Towards Linked Data
Being based on XML, OntoML is not oriented towards Linked Data
Limited number of external URLs, and they never point to structured data
Eg the Manufacturer and Supplier blocks:
Include 2 fields that characterize the Organization not the product (name of manufacturer/supplier, GLN of manufacturer/supplier)
Don't include other potentially useful Organization info (eg country, address, affiliations)
Doesn't allow linking to a separate (potentially external) Organization node
But there are tons of Linked Data about Organizations! Eg see
I understand the logic of using IRDIs instead of names for ontology terms (classes and properties):
Names are not as stable
ECLASS includes multilingual information. Although EN is the first and mandatory language, it may be better not to put it in the foundation
The largest ontology with named terms that I know of is FIBO in the financial domain: 122 ontologies, 1500 classes, 1000 properties.
But most of the huge ontologies use numbered/coded class, eg:
Wikidata
All LifeSci and Biomedical ontologies
RDA in the library domain
3.2.1 IRDI vs Named Classes/Props (Cons)
There are some considerations against using IRDI terms:
People are always happier to use understandable (English) names in their RDF data rather than opaque IDs.
Eg see RDA-Vocabularies/issues/38
In the examples below I use named terms for better understadability
Which does NOT mean that I recommend making English names
But ECLASS may decide to reuse some existing classes, properties or UoM
Then some IRDIs should be replaced with named terms
Eg schema:gtin instead of ec:0173-1_02-AAO663_003
This can be done with some lookup tables during the conversion process
3.3 IRDI Stability vs Versioning
Some props have quite a large IRDI version (last component), eg "Operating resource protection class" 0173-1#02-BAA205#012
I guess the IRDI version is incremented (upon ECLASS release time) when one of its dependencies are incremented
This leads to cascading (avalanche) incrementing:
Eg if a new country is added to the list
That Value List is incremented
All props using it are incremented
All blocks using them are incremented
All classes using the blocks are incremented
Pros: Provide precise IDs for every change of data
But: 99.9% of the time the meaning of an IRDI doesn't change, only details are added
Versioning class/property IRIs has serious drawbacks for data consumers:
It mixes product info (eg article number, GTIN) and organization info (name, GLN) into one node
It doesn't consider suppliers and manufacturers as worthy entities on their own, but as subsidiary aspects of products
It doesn't consider name, GLN as universally applicable organization attributes,
but uses properties relative to the org's role for the product (eg name of supplier, GLN of supplier)
If you consider all 5 UNSPSC Business Function Identifiers (as Martin Hepp did), would you also have name of repairer, GLN of repairer and so on for all 10 or so business functions?
It has a parasitic node :Identification that does nothing else but hold two links :supplier and :manufacturer
It pushes important product info like GTIN deep down the hierarchy
3.4.8 Blocks and Aspects Refactoring
Below I show a better way to model it, but I understand this may be hard or impossible do systematically.
We could do it for important, commonly used aspects
Or at least consider flattening such aspects to avoid parasitic links and nodes
I think that supplier is not a repeatable aspect (I didn't see cardinality),
so below I don't have per-product-per-supplier properties
But in reality may need them, since the same product may be distributed by many suppliers?
I find instance data more important (and "more interesting") as it directly tells you what the data looks like.
Now we have some basic ProductClass info and can show how a manufacturer can use it in their product catalog.
I used the empty prefix : for ECLASS props, and mf: for manufacturer props.
First I show the more natural representation using the "refactored" pattern for supplier/manufacturer.
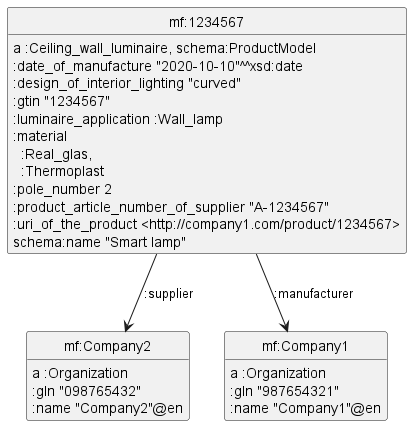
3.4.11 Catalog Entry (Refactored)
mf:1234567 a schema:ProductModel, :Ceiling_wall_luminaire;
schema:name "Smart lamp";
:manufacturer mf:Company1;
:supplier mf:Company2;
:gtin "1234567"; # or schema:gtin
:product_article_number_of_supplier "A-1234567";
:uri_of_the_product <http://company1.com/product/1234567>; # or schema:uri
:date_of_manufacture "2020-10-10"^^xsd:date;
:luminaire_application :Wall_lamp;
:design_of_interior_lighting "curved";
:pole_number 2;
:material :Real_glas, :Thermoplast.
mf:Company1 a :Organization; :name "Company1"@en; :gln "987654321".
# Add here any number of org props, like address, website, etc
mf:Company2 a :Organization; :name "Company2"@en; :gln "098765432".
# Add here any number of org props, like address, website, etc
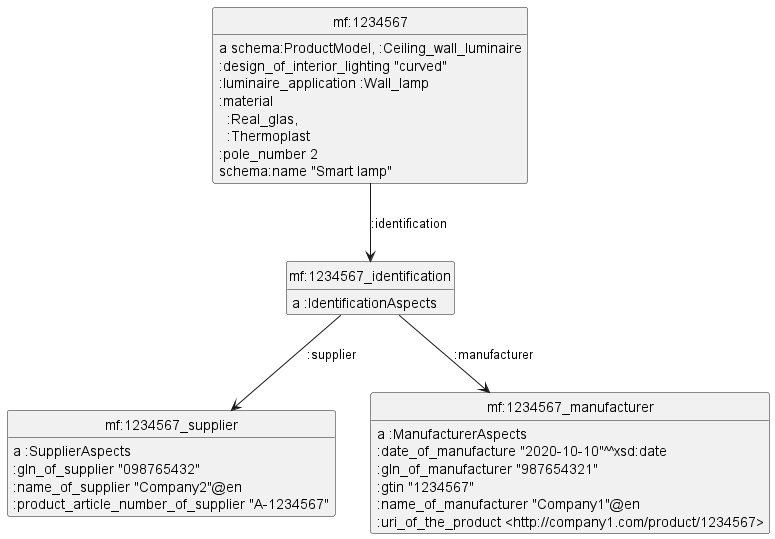
3.4.12 Catalog Entry (Not Refactored)
To appreciate that the above refactored representation is better, here's the systematic representation:
It doesn't optimize aspect structure/nesting
From the point of view of ECLASS information engineer, Advanced structure is much better than Basic because it's "divide and conquer"
But from the point of view of information consumer, mf:1234567_identification is a "parasitic" node!
It adds a level to hop through, without adding much value
I believe that most actual data uses only a small portion of all potential props and blocks
There are no separate nodes for Organizations, it all boils down to products
Thus an Organization's attributes like name, GLN are repeated in each of its products
Important product info like gtin is pushed a couple of links away from the product
3.4.13 Catalog Entry (Not Refactored)
mf:1234567 a schema:ProductModel, :Ceiling_wall_luminaire;
schema:name "Smart lamp";
:luminaire_application :Wall_lamp;
:design_of_interior_lighting "curved";
:pole_number 2;
:material :Real_glas, :Thermoplast;
:identification mf:1234567_identification.
mf:1234567_identification a :IdentificationAspects;
:manufacturer mf:1234567_manufacturer;
:supplier mf:1234567_supplier.
mf:1234567_manufacturer a :ManufacturerAspects;
:gtin "1234567"; # or schema:gtin
:uri_of_the_product <http://company1.com/product/1234567>; # or schema:uri
:date_of_manufacture "2020-10-10"^^xsd:date;
:name_of_manufacturer "Company1"@en;
:gln_of_manufacturer "987654321".
mf:1234567_supplier a :SupplierAspects;
:product_article_number_of_supplier "A-1234567";
:name_of_supplier "Company2"@en;
:gln_of_supplier "098765432".
3.4.14 Cardinality
Let's show how to represent repeated aspects ("Cardinality") on the example of Additional Information
I skipped "number of documentations" because that's redundant (one can just count the number of instances)
I'd model classes and properties as above, so we don't show them but only instance data
The only addition is :index which shows the sequential number of the additional info
We could use an rdf:List but using an :index is easier and cleaner